redis-cli创建集群流程
- 先通过CLUSTER INFO获取节点是否开启集群模式
- cluster addslots为每个master添加槽点
- CLUSTER REPLICATE为每个replicate节点与master关联
- cluster set-config-epoch为每个节点设置不同epoch
- cluster meet把节点关联起来
小于 1 分钟
分享技术丨记录生活
创建节点数据
for port in $(seq 1 6); \
do \
mkdir -p ./node-${port}/conf
touch ./node-${port}/conf/redis.conf
cat << EOF > ./node-${port}/conf/redis.conf
port 800${port}
bind 0.0.0.0
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 10.8.46.98
cluster-announce-port 800${port}
cluster-announce-bus-port 1800${port}
appendonly yes
EOF
done
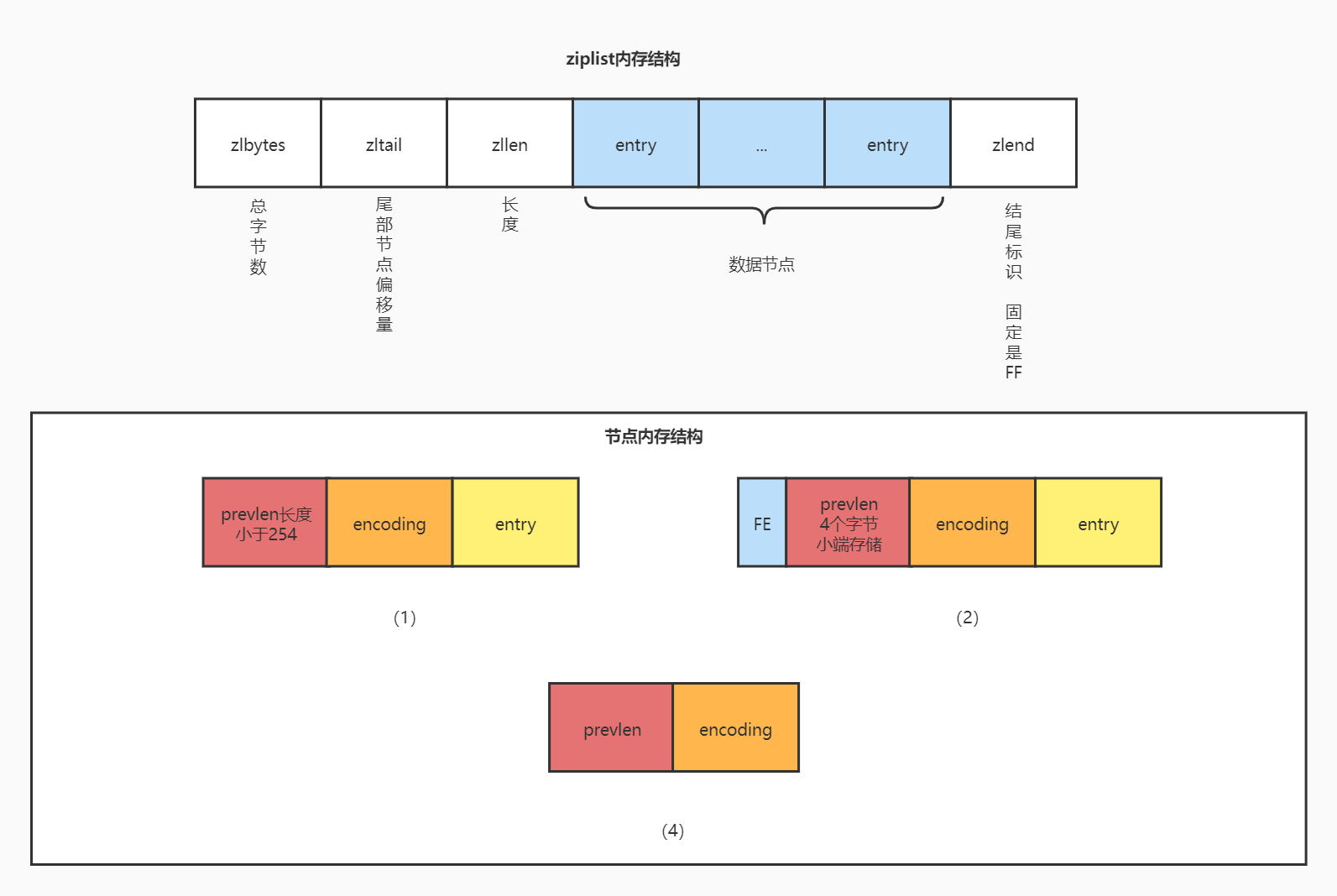
ziplist是一个用一段特殊编码实现的双向链表,优势是占用内存小,可以存储字符串类型和整数类型。在内存布局中包含一下几个字段
在分析netty堆外内存泄漏的时候,想查看堆外内存存储了些什么,所以写了这个小工具。确实gdb也可以实现,但gdb会处理其它信号,可能会影响程序的正常运行。生产配合arthas一起食用

在研究elasticsearch排序插件的时候,自研的排序算法产生的数值远远大于64位数字的最大值,所以只能选择字符串排序。
字符串是按ASCII编码排序的,对于数字排序是存在问题的。比如有一下这些数字字符串:1、2、4、12、3,排序的结果就是1、12、2、3、4。这不符合数字排序的预期,这也正是原先在做solr的时候没有选择字符串排序的原因。在查询资料的时候,找到这个贴子 https://discuss.elastic.co/t/sorting-a-string-field-numerically/9489/7 其中提供了一种方法:把数字的位数追加到原数字的前面,追加的数字需要有占位符,比如已知最长的位数不超过100,追加的数字就是有两位,01、02、12这样。为什么需要这样呢?因为在对比字符串的原理是从0下标开始取出字符做对比,先取出位数做对比就能解决数字字符串排序的问题。
com.sun.tools.javac.jvm.ClassWriter#writeClass 把字节码写出到OutputStream中
java文件-> JCCompilationUnit(类) -> 注解处理器 -> 写出class文件
简化mapstruct使用,灵感来源Spring Ioc。
<dependency>
<groupId>cn.dhbin</groupId>
<artifactId>mapstruct-helper-core</artifactId>
<version>1.0.0</version>
</dependency>
整数集合的实现相对比较简单,我们看下它的数据结构
/* 整数集合的数据结构 */
typedef struct intset {
uint32_t encoding; /* 编码,该编码决定了contents数组的int类型,支持16位、32位、64位 */
uint32_t length; /* 元素长度 */
int8_t contents[]; /* 元素,元素的类型不是int8_t,而是根据encoding动态强制转换 */
} intset;